Webinar Replay: Leveraging Historical Data for Better Software Development Estimation

If you were unable to attend our recent webinar, a replay is now available.
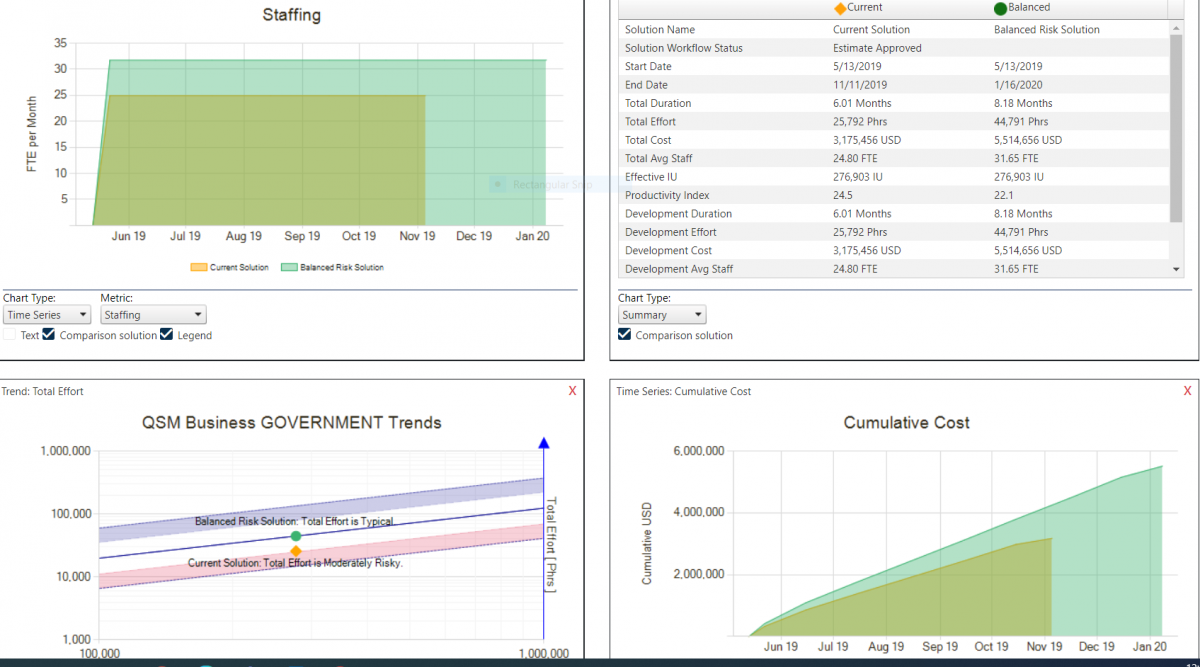
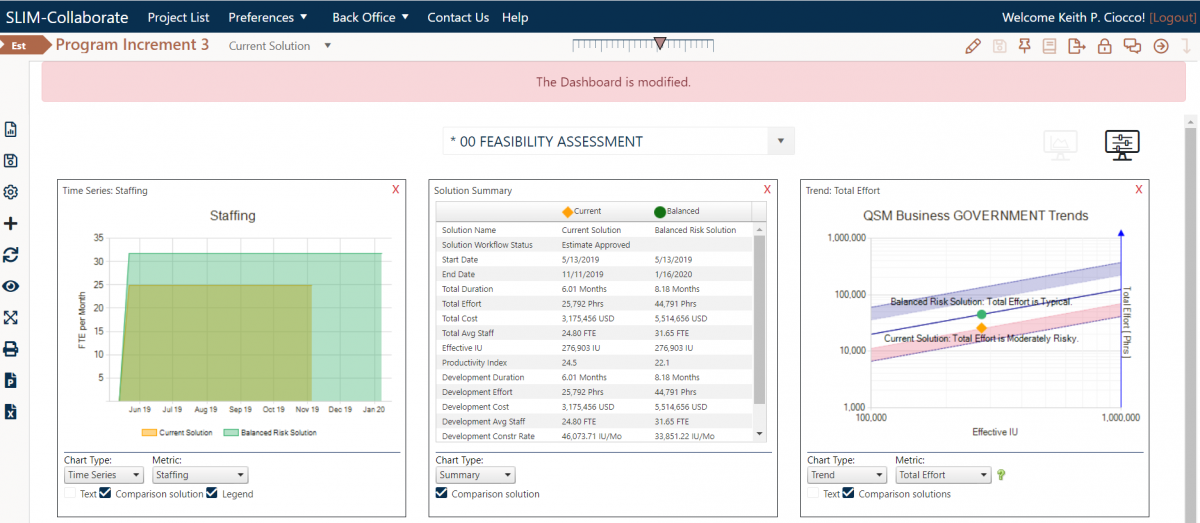
Software development managers are often in a position where they need to communicate to stakeholders what their work is going to cost and how long it will take to deliver. Unrealistic targets can be set, because decisions are made based on gut feel instead of past performance, causing projects to be late and over budget. Leveraging historical data with project planning can change all of that. In this webinar, Keith Ciocco demonstrates some of the best practices and tools that QSM uses to help clients capture and analyze historical data for better estimation, process improvement, and early decision making.
Keith Ciocco has more than 30 years of experience working in sales and customer service, with 25 of those years spent with QSM. As Vice President, his primary responsibilities include supporting QSM clients with their estimation and measurement goals, managing business development and existing client relations. He has developed and directed the implementation of the sales and customer retention process within QSM and has played a leading role in communicating the value of the QSM tools and services to professionals in the software development, engineering and IT industries.