Is Your Cloud Migration ROI Too Optimistic?
You may wonder, like I do, if companies are still planning cloud migration initiatives in 2025 and the near future. A quick internet search says “Yes.” Cloud migration is still ongoing and has even accelerated, with many organizations moving more applications to the cloud and embracing hybrid or multi-cloud strategies. While some companies are finishing their initial migrations, many others are in the process of starting new migrations.
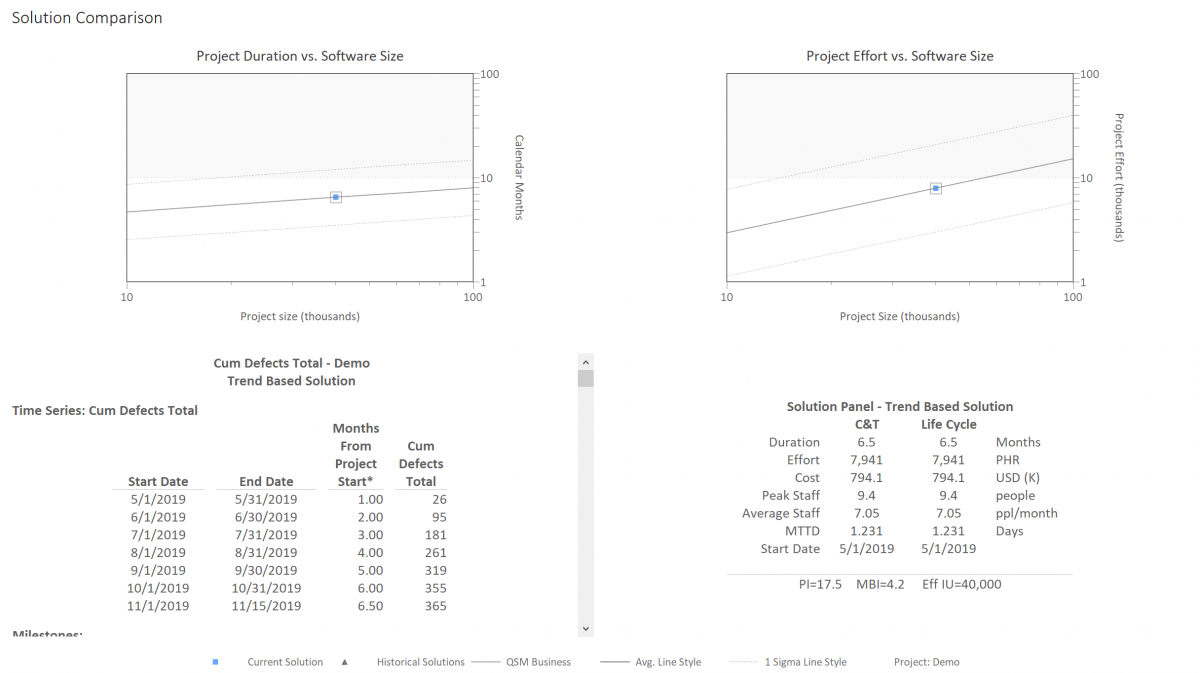
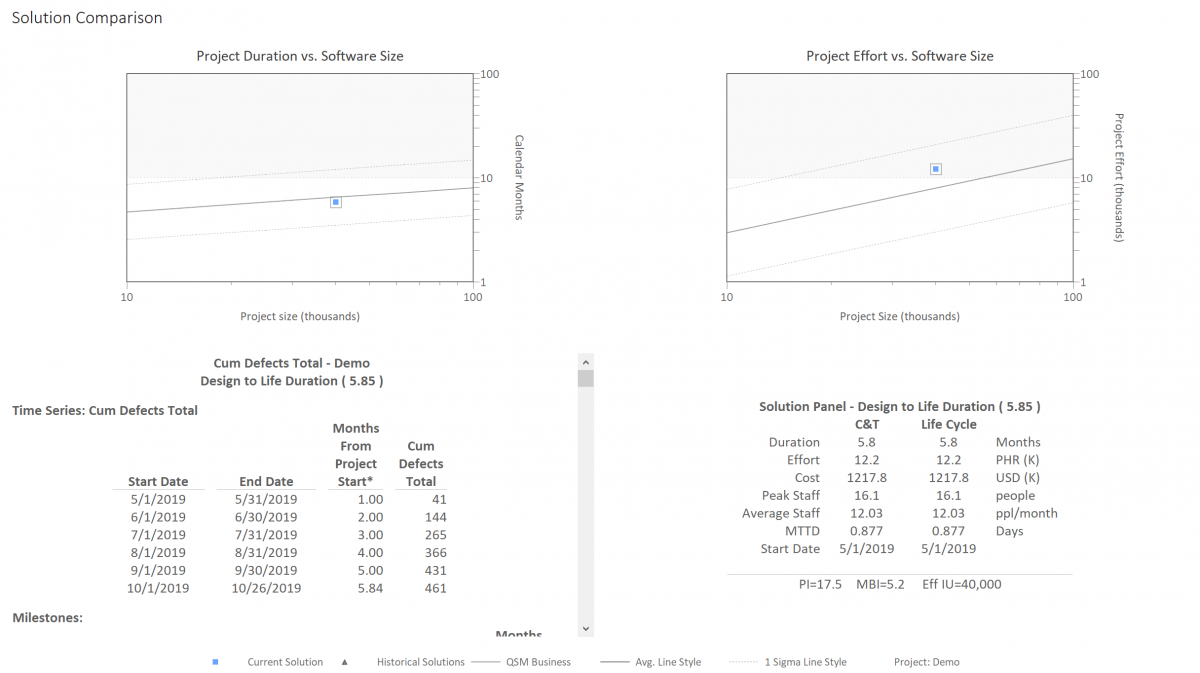
The benefits of cloud migration are numerous, fueling the expected growth of the industry. There are many cloud migration ROI “calculators” provided by major cloud platforms and solution providers that help you account for hard and soft costs, such as Amdocs, Evaluating the ROI of Cloud Migration. But few, if any, help you estimate the labor cost required to make software applications operational in a cloud environment. If your software cost estimates are too low, then your cloud migration ROI is too optimistic.