3 Ways Historical Data Improves Software Development Negotiations

How many times have you been involved with a software project or a portfolio of projects where the schedule or budget is doomed from the start? It happens all the time. One of the best ways to avoid this problem is to leverage historical data – actual performance of completed software projects. QSM has over 46 years experience in software estimation and control. We have seen thousands of projects and products delivered, both in-house and vendor driven. One of the biggest problems we help our clients solve is negotiating the right cost and schedule targets. Whether advising a client on an in-house project, a vendor on their proposal, or an end user with a bid evaluation decision, one thing becomes very clear − all sides are trying to negotiate a cost and timeline that they feel comfortable with. The problem is that they often negotiate with little to no data of past performance.
Negotiating Initial Schedule and Budget Commitments
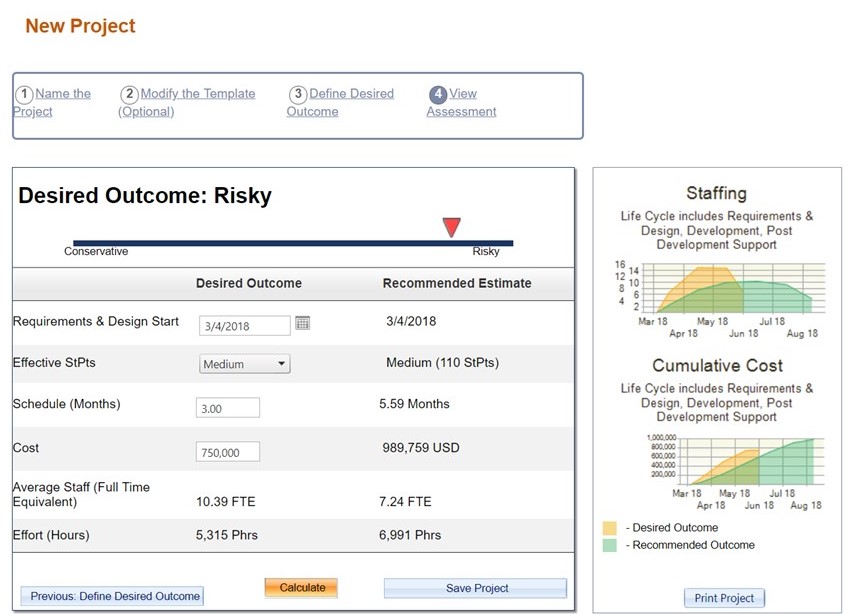
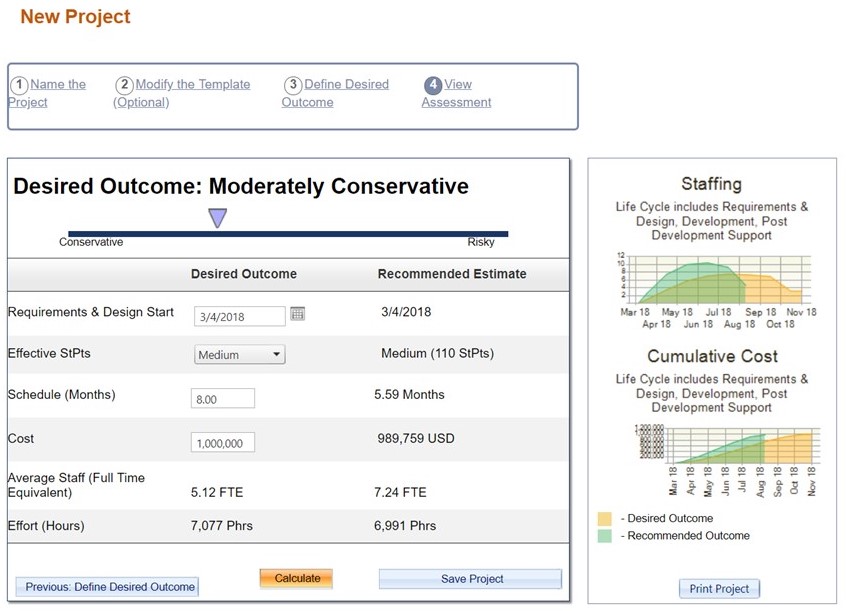
You don't need data from hundreds of projects, and it doesn’t need to be granular. Software project or release level data is a great place to start. It establishes a baseline that you can count on because the delivery targets have been achieved in the past. It is tough to argue with cost and schedule numbers that have already been proven, and of course, having the data at your fingertips gives you a leg to stand on when negotiating.
The best practice we recommend is to capture a few core metrics: